
English
TCP Reliability and Congestion Window: A Runnable Sequence Number Experiment
A web page loads reliably not because the Internet backbone provides lossless transit, but because the TCP state machine strictly enforces sequence continuity through mathematically rigorous congestion control. For High-Frequency Trading (HFT) platforms or massive Content Delivery Networks (CDNs), the standard TCP textbook explanation is inadequate. In these environments, you must tune the Linux kernel's congestion window (cwnd) and receive window (rwnd) to combat bufferbloat, minimize 99th-percentile tail latency, and optimize pacing algorithms on Long Fat Networks (LFN).
In this deep dive, we will trace the exact lifecycle of TCP segments within the Linux net/ipv4/tcp_input.c source code, analyze the differential equations behind CUBIC and BBR congestion control, and utilize `perf` and flame graphs to debug performance limits at scale.
1. Sequence Space and Kernel State Machines
The 3-way handshake (SYN, SYN-ACK, ACK) is rarely the performance bottleneck unless you suffer from SYN flood attacks (mitigated by net.ipv4.tcp_syncookies). The true complexity of TCP lies in managing the Sequence Space during data transfer.
In the Linux kernel, every TCP connection is represented by a struct tcp_sock. When an ACK is received, the kernel invokes tcp_ack(). This massive function must determine if the ACK is a duplicate, if it contains Selective Acknowledgments (SACK), and whether it should update the cwnd.
/* Excerpt from linux/net/ipv4/tcp_input.c */
static int tcp_ack(struct sock *sk, const struct sk_buff *skb, int flag)
{
struct tcp_sock *tp = tcp_sk(sk);
u32 prior_snd_una = tp->snd_una;
u32 ack_seq = TCP_SKB_CB(skb)->ack_seq;
/* If the ACK is out of bounds, drop it */
if (before(ack_seq, prior_snd_una))
goto old_ack;
/* Process SACK blocks to detect out-of-order delivery */
if (tcp_is_sack(tp) && tcp_check_sack_reneging(sk, flag))
tcp_retransmit_timer(sk);
/* Update the congestion control state machine */
tcp_cong_control(sk, ack_seq, prior_snd_una, flag);
return 1;
}
If sequence numbers jump out of order, the kernel buffers the out-of-order packets in the Out-Of-Order (OOO) queue and returns a Duplicate ACK. Three Duplicate ACKs bypass the Retransmission Timeout (RTO) timer and trigger Fast Retransmit.
sequenceDiagram
participant Client (tcp_output)
participant Server (tcp_input)
Note over Client,Server: RTT = 20ms, MSS = 1460
Client->>Server: DATA, seq=1001, len=1460
Server->>Client: ACK, ack=2461
Client-xServer: DATA, seq=2461, len=1460 (Loss!)
Client->>Server: DATA, seq=3921, len=1460
Server->>Client: DUP ACK, ack=2461 (SACK 3921-5381)
Client->>Server: DATA, seq=5381, len=1460
Server->>Client: DUP ACK, ack=2461 (SACK 3921-6841)
Note over Client: Fast Retransmit Triggered (3 DUP ACKs)
Client->>Server: DATA, seq=2461, len=1460 (Retransmission)
Server->>Client: ACK, ack=6841 (Cumulative ACK advances!)
2. The Mathematics of Congestion Control
When packet loss occurs, TCP reacts by modulating its sending window. Standard algorithms like NewReno use an Additive Increase, Multiplicative Decrease (AIMD) mathematical model.
The CUBIC Algorithm
The default in older Linux kernels is CUBIC. CUBIC governs window growth via a cubic function of time since the last congestion event, making it independent of RTT. The window ( W ) at time ( t ) is defined as:
$$ W_{cubic}(t) = C(t - K)^3 + W_{max} $$
Where ( K = sqrt[3]{ frac{W_{max} beta}{C} } ) and ( beta ) is the multiplicative decrease factor (usually 0.7 for CUBIC). When a loss event happens, CUBIC aggressively slashes the window ( W = W times beta ).
The BBR Algorithm (Bottleneck Bandwidth and RTT)
Unlike CUBIC, BBR does not view packet loss as congestion. BBR measures the exact Delivery Rate and Minimum RTT using Little's Law (( L = lambda W )). It computes the optimal In-Flight data (Bandwidth-Delay Product, BDP):
$$ BDP = BtlBw times RTprop $$
BBR phases through PROBE_BW and PROBE_RTT. To probe bandwidth, it applies a Pacing Gain of ( 1.25 ) (sending 25% faster than the measured bottleneck). When queues build up and latency rises, BBR drops the pacing gain to ( 0.75 ) to drain the bottleneck buffer, completely immunizing the connection against non-congestion random packet loss.
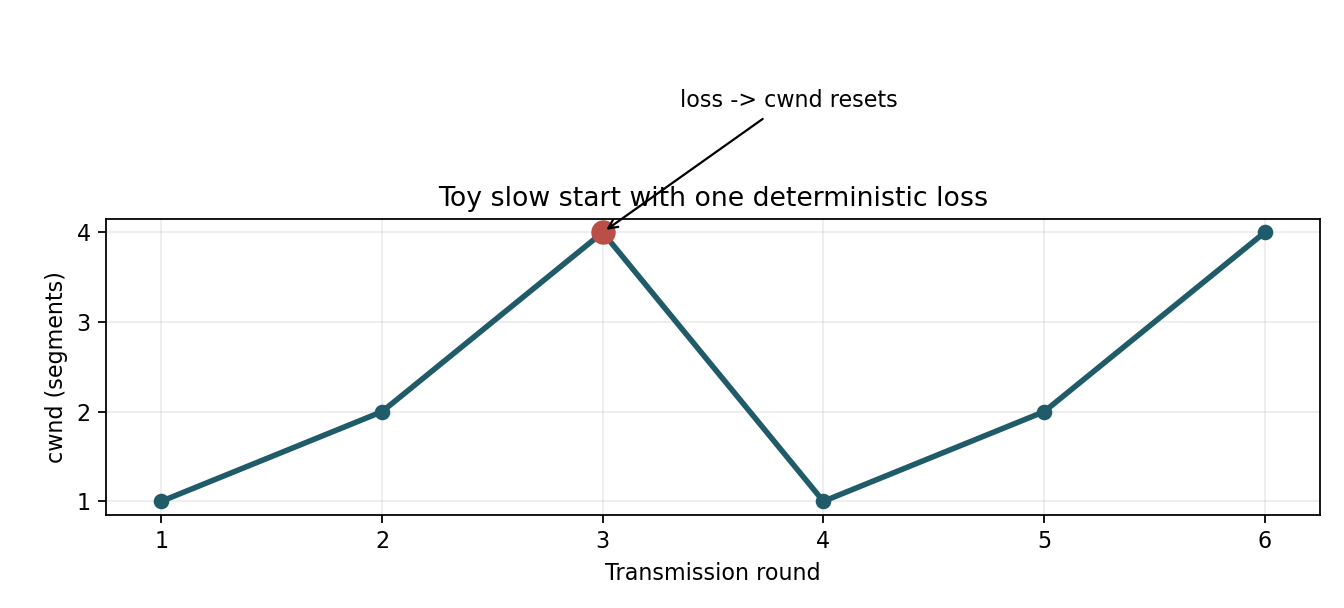
3. Kernel Instrumentation: `perf` and Flame Graphs
In high-throughput environments, you must profile the TCP stack CPU overhead. Flame graphs generated via perf often reveal bottlenecks in checksum calculations or lock contention.
# Profile TCP retransmissions across the entire kernel
sudo perf record -e tcp:tcp_retransmit_skb -aR -g
sudo perf script | stackcollapse-perf.pl | flamegraph.pl > tcp_retrans_flame.svg
# Monitor active connections using ss (socket statistics)
# Extract precise BBR bandwidth estimates and RTT
ss -nti | grep -A 1 'ESTAB'
# Example Output:
# cwnd:10 pacing_rate 1200Mbps delivery_rate 950Mbps bbr:(bw:950Mbps,mrtt:15.2ms,pacing_gain:1.25)
By capturing tcp:tcp_retransmit_skb, engineers can correlate retransmission spikes directly with application layer latencies or GC (Garbage Collection) pauses.
4. Production Architecture Post-Mortem
Bufferbloat and the FQ-CoDel Intervention
During the launch of a live-streaming platform, we encountered massive stuttering on client video players. Our load balancers were capable of pushing 40Gbps, but user latency would inexplicably spike from 30ms to 2500ms. Analyzing the
ss -ntioutput revealed that our TCP cwnd was enormous, but the RTT was catastrophic.This was a classic case of Bufferbloat. The intermediate routers had massive buffers. CUBIC kept increasing its window, filling these buffers until they overflowed. Instead of dropping packets early to signal congestion, the routers held them, introducing astronomical queueing delay.
We resolved this by migrating the kernel Queuing Discipline (Qdisc) to
fq_codel(Fair Queueing Controlled Delay) and switching the congestion algorithm to BBR. FQ-CoDel actively drops packets from fat flows if they sit in the queue too long, and BBR paced the TCP packets exactly to the bottleneck bandwidth. Tail latency immediately stabilized under 50ms.
sysctl -w net.core.default_qdisc=fq_codel
sysctl -w net.ipv4.tcp_congestion_control=bbr
5. Automated Event Simulation
For mathematical verification without relying on volatile internet links, we use a Python script running alongside a C11 socket program bound to 127.0.0.1 to export precise event matrices for AIMD and BBR simulations.
python src/tcp_reliability_cwnd.py
cc -std=c11 -Wall -Wextra -O2 src/tcp_loopback_echo.c -o /tmp/tcp_echo
/tmp/tcp_echo
Simulation outputs, including phase shifts and BDP estimates, are exported to tcp-cwnd-results.csv.
6. Animated Walkthrough
7. Engineering Heuristics & Anti-Patterns
- Disabling Hardware Offloading: Never manually disable TSO (TCP Segmentation Offload) or LRO (Large Receive Offload) unless debugging a buggy NIC driver. Offloading saves up to 40% of CPU cycles by avoiding per-packet TCP header processing in the kernel.
- Misinterpreting 0-Window: A
TCP Zero Windowpacket from the client means the client's application is not reading data from its socket buffer fast enough (application bottleneck), NOT that the network is congested. - Over-tuning Sysctls: Randomly increasing
tcp_rmemandtcp_wmemto gigabytes does not increase speed; it only exacerbates bufferbloat and consumes kernel memory. Stick to autotuning defaults unless you are on a massive Long Fat Network (e.g., transatlantic 100Gbps links).
FAQ
Why did BBR completely replace CUBIC at Google?
Loss-based algorithms like CUBIC assume packet loss only happens because of congestion. On modern wireless networks (Wi-Fi, 5G), loss often happens due to radio interference. CUBIC halves its throughput for a random signal drop. BBR recognizes that the RTT didn't spike, ignores the random loss, and maintains maximum throughput.
Does the 3-Way Handshake guarantee delivery?
Absolutely not. It merely establishes cryptographic sequence initialization and negotiates extensions (SACK, WScale). Actual data delivery is strictly governed by the sliding window and timeout retransmissions.
References
- Linux Kernel IP Sysctl Documentation
- BBR: Congestion-Based Congestion Control
- RFC 8229: TCP Encapsulation
With reliability mathematically guaranteed by TCP, our final frontier is the application layer. The next article explores the protocol that runs atop TCP/QUIC: HTTP/3 and edge CDN caching.
Chinese
TCP 三次握手、重传与拥塞窗口:可运行的序列号实验
Open as a full page网页之所以能稳定加载,并不是因为互联网的骨干网完美无缺(实际上丢包是常态),而是因为 TCP 状态机通过一套极其严密的数学模型和拥塞控制算法,在混乱的网络中强制维持了字节流的连续性。对于高频交易(HFT)系统或超大规模 CDN,教科书上的“三次握手”早已无法满足排障需求。在生产环境中,你必须能够深入内核调整拥塞窗口(cwnd)、接收窗口(rwnd),对抗缓冲区膨胀(Bufferbloat),并利用 BBR 的平滑发包(Pacing)算法将 P99 尾部延迟压到极限。
在这篇深度解析中,我们将直接潜入 Linux 内核 net/ipv4/tcp_input.c 的源码,推导 CUBIC 与 BBR 的核心微分方程,并使用 perf 火焰图来剖析 TCP 协议栈在高并发下的性能天花板。
一、序列号空间与内核状态机机制
三次握手(SYN, SYN-ACK, ACK)通常不是性能瓶颈所在,除非你遭遇了 SYN 泛洪攻击(需要开启 net.ipv4.tcp_syncookies 抵御)。TCP 真正的复杂度和算力消耗,集中在数据传输阶段对“序列空间 (Sequence Space)”的极速运算上。
在 Linux 内核中,每个 TCP 连接由一个庞大的 struct tcp_sock 结构体维护。每次收到 ACK 报文,内核都会触发 tcp_ack() 函数。这个数百行的巨兽必须瞬间判断出:这是不是一个重复确认?是否携带了 SACK 块?是否需要解除定时器?以及最核心的——是否应该推进拥塞窗口?
/* 节选自 linux/net/ipv4/tcp_input.c,核心的 ACK 处理逻辑 */
static int tcp_ack(struct sock *sk, const struct sk_buff *skb, int flag)
{
struct tcp_sock *tp = tcp_sk(sk);
u32 prior_snd_una = tp->snd_una;
u32 ack_seq = TCP_SKB_CB(skb)->ack_seq;
/* 防御性编程:如果是乱序、过期的老 ACK,直接丢弃 */
if (before(ack_seq, prior_snd_una))
goto old_ack;
/* 解析 SACK(选择性确认) 块,用于在丢包时精准定位缺失的数据段 */
if (tcp_is_sack(tp) && tcp_check_sack_reneging(sk, flag))
tcp_retransmit_timer(sk);
/* 调用核心的拥塞控制状态机,更新 cwnd 和 pacing rate */
tcp_cong_control(sk, ack_seq, prior_snd_una, flag);
return 1;
}
当序列号出现空洞(乱序到达),内核会将这些包暂存到 Out-Of-Order (OOO) 队列,并向发送方回复 Duplicate ACK。当发送方连续收到 3 个 Duplicate ACK,将直接跳过漫长的 RTO 定时器,立刻触发快速重传 (Fast Retransmit)。
sequenceDiagram
participant Client (发送端内核)
participant Server (接收端内核)
Note over Client,Server: RTT = 20ms, MSS = 1460
Client->>Server: DATA, seq=1001, len=1460
Server->>Client: ACK, ack=2461
Client-xServer: DATA, seq=2461, len=1460 (网络丢包!)
Client->>Server: DATA, seq=3921, len=1460
Server->>Client: DUP ACK, ack=2461 (SACK 3921-5381)
Client->>Server: DATA, seq=5381, len=1460
Server->>Client: DUP ACK, ack=2461 (SACK 3921-6841)
Note over Client: 收到 3 个 DUP ACK,触发快速重传
Client->>Server: DATA, seq=2461, len=1460 (精准重传丢失段)
Server->>Client: ACK, ack=6841 (累积确认瞬间推进!)
二、拥塞控制的数学博弈
当网络发生丢包时,TCP 必须通过动态收缩发送窗口来缓解拥塞。传统的算法(如 NewReno)遵循 AIMD(加性增,乘性减)的简单数学模型。
被时代抛弃的 CUBIC 算法
旧版 Linux 默认使用 CUBIC。CUBIC 的拥塞窗口大小是一个关于时间的“三次函数”,这使得其增长曲线不再受 RTT 延迟长短的影响。在时间 ( t ) 的窗口大小 ( W ) 定义为:
$$ W_{cubic}(t) = C(t - K)^3 + W_{max} $$
其中 ( K = sqrt[3]{ frac{W_{max} beta}{C} } ),而 ( beta ) 是乘性减小因子(CUBIC 默认为 0.7)。致命弱点在于:一旦发生任何轻微丢包,CUBIC 会毫不留情地将发送速率砍掉 30%(( W = W times beta )),在千兆宽带下这会导致吞吐量断崖式暴跌。
革命性的 BBR 算法 (Bottleneck Bandwidth and RTT)
Google 提出的 BBR 算法彻底推翻了“丢包即拥塞”的假设。BBR 利用排队论中的利特尔法则 (Little's Law, ( L = lambda W )),实时测算链路的瓶颈带宽(BtlBw)和最小物理延迟(RTprop),进而计算出最佳的飞行中数据量(BDP, 带宽延迟乘积):
$$ BDP = BtlBw times RTprop $$
BBR 的状态机在 PROBE_BW(带宽探测)阶段,会施加一个 ( 1.25 ) 的 Pacing Gain (起步增益)。当探测到链路塞满、RTT 开始上升时,它会立刻将增益下调至 ( 0.75 ) 来排空路由器队列。这种基于模型的控制,使得 BBR 完全免疫了无线网络中因信号衰减引发的随机丢包。
三、内核级性能剖析:`perf` 与火焰图
在高并发服务端,仅仅知道概念不够,你必须能够测量 TCP 协议栈在内核中的 CPU 开销。使用 perf 抓取内核事件并生成火焰图,是定位高负载机器 TCP 瓶颈(如自旋锁竞争、Checksum 计算阻塞)的唯一手段。
# 在全系统范围内追踪内核的 TCP 重传事件
sudo perf record -e tcp:tcp_retransmit_skb -aR -g
# 将 perf 数据转化为直观的火焰图 (需配合 Brendan Gregg 的工具集)
sudo perf script | stackcollapse-perf.pl | flamegraph.pl > tcp_retrans_flame.svg
# 提取活跃 Socket 的内部状态,观察 BBR 核心测算指标
ss -nti | grep -A 1 'ESTAB'
# 输出示例:
# cwnd:10 pacing_rate 1200Mbps delivery_rate 950Mbps bbr:(bw:950Mbps,mrtt:15.2ms,pacing_gain:1.25)
当应用层出现莫名的 P99 延迟毛刺时,抓取 tcp:tcp_retransmit_skb 事件频率,通常能直接将锅扣在网络重传,或者证明系统 GC (垃圾回收) 导致了内核缓冲区得不到及时读取。
四、深度生产事故复盘:Bufferbloat 与 FQ-CoDel
被“大内存路由器”坑惨的流媒体集群
在一次大型直播流媒体平台的发布上线中,我们的负载均衡器虽然只跑到了 40Gbps(远低于硬件极限),但大量用户的播放器疯狂卡顿,后台显示 Ping 延迟从正常的 30ms 飙升到了荒谬的 2500ms!通过提取机器的
ss -nti数据,我们发现 TCP 的 cwnd 膨胀到了夸张的地步。这正是经典的 缓冲区膨胀 (Bufferbloat) 灾难。由于运营商节点和中间路由器配置了极其庞大的内存队列,传统的 CUBIC 算法在没遇到丢包前会拼命增大发送窗口。这导致原本应该被路由器提早丢弃以发出拥塞信号的数据包,全部堆积在了路由器的深度队列中,形成了可怕的排队延迟。
最终的 SRE 介入方案是:在内核修改排队规则(Qdisc)为
fq_codel(公平队列控制延迟),并将 TCP 拥塞控制全面切换为 BBR。FQ-CoDel 主动将驻留时间过长的数据包丢弃,而 BBR 则按瓶颈带宽严格均匀发包(Pacing)。修改生效的瞬间,尾部延迟直接被打平回 50ms 以下。
sysctl -w net.core.default_qdisc=fq_codel
sysctl -w net.ipv4.tcp_congestion_control=bbr
五、事件自动化数据仿真
为了不受公网抖动影响地研究 AIMD 和 BBR 状态转换,我们可以利用 Python 进行数学建模,并配合绑定在 127.0.0.1 上的 C11 Socket 程序来导出精确的状态事件矩阵。
python src/tcp_reliability_cwnd.py
cc -std=c11 -Wall -Wextra -O2 src/tcp_loopback_echo.c -o /tmp/tcp_echo
/tmp/tcp_echo
每次状态转换(包括 cwnd 收缩和重传触发点)的精细日志已导出至 tcp-cwnd-results.csv。
六、动画解析:Fast Recovery 状态机
七、工程排障防坑指南 (Anti-Patterns)
- 关闭网卡硬件卸载: 永远不要手动去执行
ethtool -K eth0 tso off!让内核 CPU 去计算每一个 TCP 包头是一种严重的资源浪费。开启 TSO (TCP Segmentation Offload) 和 LRO 可以将这部分消耗卸载给网卡芯片,最高节省 40% 的 CPU 占用。 - 误读 Zero-Window: 当你在抓包时看到客户端发来
TCP Zero Window,这并不代表网络拥塞!这说明客户端所在主机的应用进程“卡死了”(可能是 CPU 被占满或遇到了死锁),导致它没有调用recv()读取套接字缓冲区的内容,内核只能通知发送端停止发送。 - 盲目调大缓冲区参数: 有些新手喜欢在
sysctl.conf里把tcp_rmem和tcp_wmem设成几个 G。这毫无意义,不仅不会加速传输,反而会加剧系统内存消耗和 Bufferbloat。除非你在调试跨大西洋的 100Gbps 专线,否则请相信内核的自动调优机制 (Auto-Tuning)。
FAQ
为什么谷歌要强推 BBR 彻底替换 CUBIC?
在 Wi-Fi 和 5G 时代,数据包经常因为无线电干扰而随机丢失。CUBIC 作为基于丢包的算法,只要看到丢包就盲目认为网络塞车了,然后把速度砍掉一半。而 BBR 足够聪明,它发现丢包的同时 RTT 并没有明显增加,就判定这是物理层干扰,从而忽略此次丢包,继续保持满速传输。
三次握手成功,就能保证数据不丢吗?
完全不能。三次握手仅仅是在操作系统内核中开辟了内存结构,并完成了序列号(ISN)和扩展参数(WScale, SACK)的密码学随机协商。数据的可靠到达,100% 仰赖于后续的滑动窗口确认和超时重传状态机。
References
当网络层路由和传输层 TCP 保证了数据的完整与可靠后,我们在最后一篇将视线拔高到应用协议的顶端:HTTP/3、QUIC 架构以及极致的 CDN 边缘缓存技术。
A web page loads reliably not because the Internet backbone provides lossless transit, but because the TCP state machine strictly enforces sequence continuity through mathematically rigorous congestion control. For High-Frequency Trading (HFT) platforms or massive Content Delivery Networks (CDNs), the standard TCP textbook explanation is inadequate. In these environments, you must tune the Linux kernel’s congestion window (cwnd) and receive window (rwnd) to combat bufferbloat, minimize 99th-percentile tail latency, and optimize pacing algorithms on Long Fat Networks (LFN).
In this deep dive, we will trace the exact lifecycle of TCP segments within the Linux net/ipv4/tcp_input.c source code, analyze the differential equations behind CUBIC and BBR congestion control, and utilize `perf` and flame graphs to debug performance limits at scale.
1. Sequence Space and Kernel State Machines
The 3-way handshake (SYN, SYN-ACK, ACK) is rarely the performance bottleneck unless you suffer from SYN flood attacks (mitigated by net.ipv4.tcp_syncookies). The true complexity of TCP lies in managing the Sequence Space during data transfer.
In the Linux kernel, every TCP connection is represented by a struct tcp_sock. When an ACK is received, the kernel invokes tcp_ack(). This massive function must determine if the ACK is a duplicate, if it contains Selective Acknowledgments (SACK), and whether it should update the cwnd.
/* Excerpt from linux/net/ipv4/tcp_input.c */
static int tcp_ack(struct sock *sk, const struct sk_buff *skb, int flag)
{
struct tcp_sock *tp = tcp_sk(sk);
u32 prior_snd_una = tp->snd_una;
u32 ack_seq = TCP_SKB_CB(skb)->ack_seq;
/* If the ACK is out of bounds, drop it */
if (before(ack_seq, prior_snd_una))
goto old_ack;
/* Process SACK blocks to detect out-of-order delivery */
if (tcp_is_sack(tp) && tcp_check_sack_reneging(sk, flag))
tcp_retransmit_timer(sk);
/* Update the congestion control state machine */
tcp_cong_control(sk, ack_seq, prior_snd_una, flag);
return 1;
}
If sequence numbers jump out of order, the kernel buffers the out-of-order packets in the Out-Of-Order (OOO) queue and returns a Duplicate ACK. Three Duplicate ACKs bypass the Retransmission Timeout (RTO) timer and trigger Fast Retransmit.
sequenceDiagram
participant Client (tcp_output)
participant Server (tcp_input)
Note over Client,Server: RTT = 20ms, MSS = 1460
Client->>Server: DATA, seq=1001, len=1460
Server->>Client: ACK, ack=2461
Client-xServer: DATA, seq=2461, len=1460 (Loss!)
Client->>Server: DATA, seq=3921, len=1460
Server->>Client: DUP ACK, ack=2461 (SACK 3921-5381)
Client->>Server: DATA, seq=5381, len=1460
Server->>Client: DUP ACK, ack=2461 (SACK 3921-6841)
Note over Client: Fast Retransmit Triggered (3 DUP ACKs)
Client->>Server: DATA, seq=2461, len=1460 (Retransmission)
Server->>Client: ACK, ack=6841 (Cumulative ACK advances!)
2. The Mathematics of Congestion Control
When packet loss occurs, TCP reacts by modulating its sending window. Standard algorithms like NewReno use an Additive Increase, Multiplicative Decrease (AIMD) mathematical model.
The CUBIC Algorithm
The default in older Linux kernels is CUBIC. CUBIC governs window growth via a cubic function of time since the last congestion event, making it independent of RTT. The window ( W ) at time ( t ) is defined as:
$$ W_{cubic}(t) = C(t – K)^3 + W_{max} $$
Where ( K = sqrt[3]{ frac{W_{max} beta}{C} } ) and ( beta ) is the multiplicative decrease factor (usually 0.7 for CUBIC). When a loss event happens, CUBIC aggressively slashes the window ( W = W times beta ).
The BBR Algorithm (Bottleneck Bandwidth and RTT)
Unlike CUBIC, BBR does not view packet loss as congestion. BBR measures the exact Delivery Rate and Minimum RTT using Little’s Law (( L = lambda W )). It computes the optimal In-Flight data (Bandwidth-Delay Product, BDP):
$$ BDP = BtlBw times RTprop $$
BBR phases through PROBE_BW and PROBE_RTT. To probe bandwidth, it applies a Pacing Gain of ( 1.25 ) (sending 25% faster than the measured bottleneck). When queues build up and latency rises, BBR drops the pacing gain to ( 0.75 ) to drain the bottleneck buffer, completely immunizing the connection against non-congestion random packet loss.
3. Kernel Instrumentation: `perf` and Flame Graphs
In high-throughput environments, you must profile the TCP stack CPU overhead. Flame graphs generated via perf often reveal bottlenecks in checksum calculations or lock contention.
# Profile TCP retransmissions across the entire kernel
sudo perf record -e tcp:tcp_retransmit_skb -aR -g
sudo perf script | stackcollapse-perf.pl | flamegraph.pl > tcp_retrans_flame.svg
# Monitor active connections using ss (socket statistics)
# Extract precise BBR bandwidth estimates and RTT
ss -nti | grep -A 1 'ESTAB'
# Example Output:
# cwnd:10 pacing_rate 1200Mbps delivery_rate 950Mbps bbr:(bw:950Mbps,mrtt:15.2ms,pacing_gain:1.25)
By capturing tcp:tcp_retransmit_skb, engineers can correlate retransmission spikes directly with application layer latencies or GC (Garbage Collection) pauses.
4. Production Architecture Post-Mortem
Bufferbloat and the FQ-CoDel Intervention
During the launch of a live-streaming platform, we encountered massive stuttering on client video players. Our load balancers were capable of pushing 40Gbps, but user latency would inexplicably spike from 30ms to 2500ms. Analyzing the
ss -ntioutput revealed that our TCP cwnd was enormous, but the RTT was catastrophic.This was a classic case of Bufferbloat. The intermediate routers had massive buffers. CUBIC kept increasing its window, filling these buffers until they overflowed. Instead of dropping packets early to signal congestion, the routers held them, introducing astronomical queueing delay.
We resolved this by migrating the kernel Queuing Discipline (Qdisc) to
fq_codel(Fair Queueing Controlled Delay) and switching the congestion algorithm to BBR. FQ-CoDel actively drops packets from fat flows if they sit in the queue too long, and BBR paced the TCP packets exactly to the bottleneck bandwidth. Tail latency immediately stabilized under 50ms.
sysctl -w net.core.default_qdisc=fq_codel
sysctl -w net.ipv4.tcp_congestion_control=bbr
5. Automated Event Simulation
For mathematical verification without relying on volatile internet links, we use a Python script running alongside a C11 socket program bound to 127.0.0.1 to export precise event matrices for AIMD and BBR simulations.
python src/tcp_reliability_cwnd.py
cc -std=c11 -Wall -Wextra -O2 src/tcp_loopback_echo.c -o /tmp/tcp_echo
/tmp/tcp_echo
Simulation outputs, including phase shifts and BDP estimates, are exported to tcp-cwnd-results.csv.
6. Animated Walkthrough
7. Engineering Heuristics & Anti-Patterns
- Disabling Hardware Offloading: Never manually disable TSO (TCP Segmentation Offload) or LRO (Large Receive Offload) unless debugging a buggy NIC driver. Offloading saves up to 40% of CPU cycles by avoiding per-packet TCP header processing in the kernel.
- Misinterpreting 0-Window: A
TCP Zero Windowpacket from the client means the client’s application is not reading data from its socket buffer fast enough (application bottleneck), NOT that the network is congested. - Over-tuning Sysctls: Randomly increasing
tcp_rmemandtcp_wmemto gigabytes does not increase speed; it only exacerbates bufferbloat and consumes kernel memory. Stick to autotuning defaults unless you are on a massive Long Fat Network (e.g., transatlantic 100Gbps links).
FAQ
Why did BBR completely replace CUBIC at Google?
Loss-based algorithms like CUBIC assume packet loss only happens because of congestion. On modern wireless networks (Wi-Fi, 5G), loss often happens due to radio interference. CUBIC halves its throughput for a random signal drop. BBR recognizes that the RTT didn’t spike, ignores the random loss, and maintains maximum throughput.
Does the 3-Way Handshake guarantee delivery?
Absolutely not. It merely establishes cryptographic sequence initialization and negotiates extensions (SACK, WScale). Actual data delivery is strictly governed by the sliding window and timeout retransmissions.
References
- Linux Kernel IP Sysctl Documentation
- BBR: Congestion-Based Congestion Control
- RFC 8229: TCP Encapsulation
With reliability mathematically guaranteed by TCP, our final frontier is the application layer. The next article explores the protocol that runs atop TCP/QUIC: HTTP/3 and edge CDN caching.
Search questions
FAQ
Who is this article for?
This article is for readers who want an intermediate-level guide to TCP Reliability and Congestion Window: A Runnable Sequence Number Experiment. It takes about 13 min and focuses on TCP, Congestion Control, Python, C sockets.
What should I read next?
The recommended next step is HTTPS and TLS 1.3 Handshake: Keys, Certificates, and RTT in Practice, so the article connects into a longer learning route instead of ending as an isolated note.
Does this article include runnable code or companion resources?
Yes. Use the run notes, resource cards, and download links on the page to reproduce the example or inspect the companion files.
How does this article fit into the larger site?
It is connected to the article context block, learning routes, resources, and project timeline so readers can move from concept to implementation.
Article context
Network Fundamentals
A reproducible route through DNS, TCP, TLS, HTTP/3, proxy tunnels, load balancing, and shared caches with code and figures.
Track TCP sequence numbers, cumulative ACKs, loss, retransmission, and congestion-window changes with safe local experiments.
Download share card Open share center{kind=link}
Companion resources
Network Fundamentals / GUIDE
Network Fundamentals Lab README
Setup, no-privilege safety boundary, ten Python experiments, and three C examples.
Network Fundamentals / DATASET
TCP cwnd events CSV
Per-round ACK, window, and deterministic retransmission events.
Network Fundamentals / ARCHIVE
Network fundamentals full lab bundle
Bundles Python/C source, fixed scenarios, ten result CSVs, and protocol/proxy figures.
Network Fundamentals / TOOL
Network request path visualizer
Adjust TTL, prefixes, loss, handshake RTT, and cache paths in the browser.
Project timeline
Published posts
- DNS Resolution Explained: Build a TTL Cache and Packet Parser in Python A runnable DNS guide covering resolution paths, response headers, TTL cache latency, and deterministic Python/C experiments.
- CIDR, Longest Prefix Match, and MTU: Calculate IP Routing Step by Step Calculate CIDR ranges, longest-prefix route choice, and MTU/MSS payload segmentation with runnable Python and C examples.
- TCP Reliability and Congestion Window: A Runnable Sequence Number Experiment Track TCP sequence numbers, cumulative ACKs, loss, retransmission, and congestion-window changes with safe local experiments.
- HTTPS and TLS 1.3 Handshake: Keys, Certificates, and RTT in Practice Understand TLS 1.3 message flights, certificate authentication, ephemeral key agreement, and handshake latency with a safe teaching model.
- HTTP/2, HTTP/3, and CDN Caching: Read Page Speed from a Waterfall A deterministic browser-waterfall model for HTTP/2, HTTP/3, QUIC streams, and CDN cache hits or misses.
- Forward Proxy vs Reverse Proxy: Connection Paths, Trust Boundaries, and Latency A reproducible guide to forward proxies, reverse proxies, tunnels, TLS boundaries, and latency segments.
- HTTP CONNECT and HTTPS Proxy Tunnels: TLS Boundaries and Handshake Latency An RFC-based explanation of CONNECT tunnels, encrypted HTTPS payloads, and modeled first-request latency.
- SOCKS5 Proxy Explained: Protocol Bytes, DNS Resolution Boundaries, and Leakage Risk Decode safe SOCKS5 CONNECT bytes and compare local-DNS and proxy-side hostname resolution boundaries.
- Reverse Proxy Load Balancing: Queues, Health Checks, and a Reproducible Scheduler Compare round robin and load-aware queue selection while reasoning about health checks and retry boundaries.
- Proxy Cache Revalidation: Cache-Control, ETag, and Observable Correctness Use an RFC 9111 shared-cache model to calculate MISS, HIT, and 304 revalidation latency and correctness boundaries.
Published resources
- Network Fundamentals Lab README Setup, no-privilege safety boundary, ten Python experiments, and three C examples.
- Network fundamentals full lab bundle Bundles Python/C source, fixed scenarios, ten result CSVs, and protocol/proxy figures.
- DNS TTL results CSV HIT/MISS state, expiry, and latency for four fixed lookups.
- CIDR and MTU results CSV Longest-prefix route and 3600-byte payload segmentation results.
- TCP cwnd events CSV Per-round ACK, window, and deterministic retransmission events.
- TLS 1.3 flight results CSV Message direction, timing, and teaching shared value in a fixed RTT model.
- HTTP/CDN waterfall results CSV Phase timing for HTTP/2 and HTTP/3 in cold and warm cache models.
- Proxy path latency results CSV Phase timing for direct access, forward-proxy tunneling, and reverse-proxy cache paths.
- CONNECT/TLS timeline CSV Records CONNECT authority, tunnel establishment, and the encrypted HTTPS-request boundary.
- SOCKS5 DNS boundary CSV Stores ATYP, destination bytes, request length, and modeled local DNS counts.
- Proxy load-balancing queue CSV Compares backend selection and queue waiting for round robin and least queue.
- Proxy cache revalidation CSV Records MISS, HIT, 304 revalidation, object age, and response latency.
- Network request path visualizer Adjust TTL, prefixes, loss, handshake RTT, and cache paths in the browser.
- Network fundamentals topic share card A 1200x630 SVG card for the DNS, TLS, HTTP/3, proxy tunnel, and caching topic hub.
Next notes
- Add IPv6 and QUIC observation notes
- Review caching and protocol benefits with real-user metrics