
Battery Modeling for AI
This topic connects battery simulation, impedance features, aging labels, and machine learning workflows. The point is not to treat a cell model as a black-box data generator. A useful battery AI workflow needs to explain where labels come from, which operating conditions were simulated, how parameters were varied, and why a model trained on one split should or should not generalize to another cell, cycle range, or temperature range.
The route starts with PyBaMM architecture and parameter values, then moves into EIS data generation, aging simulation, feature tables, and supervised learning for SOH or RUL-style targets. Readers should be able to inspect both the physical assumptions and the machine learning assumptions before trusting any prediction.
How to Read This Route
Begin with the modeling articles if you are new to electrochemical simulation. Understand what a model, parameter set, experiment, and solver are doing before you export features. Then read the EIS and aging dataset articles as data pipeline examples: frequency sweeps, SOC windows, metadata, label definitions, and train/test isolation matter as much as the downstream regressor.
If you come from machine learning, pay attention to leakage. Splitting rows at random can make a battery dataset look better than it is if cycles, cells, or parameter regimes appear in both train and test data. If you come from battery modeling, pay attention to feature reproducibility, dependency versions, and the gap between simulated labels and measured field data.
Reproducibility and Limits
- Record PyBaMM, Python, NumPy, pandas, and scikit-learn versions before comparing results.
- Keep simulation data, public datasets, and real device data separate in your notes.
- Check whether the validation split is isolated by cell, cycle, time, or operating condition.
- Do not use educational model outputs as production BMS decisions without domain review.
What Counts as a Useful Dataset
A useful battery AI dataset is more than a table with many rows. It should describe the simulated or measured operating conditions, the model or device source, the parameter variations, the frequency range for impedance data, the cycle or time index, and the exact label definition. Without those details, a model can look accurate while learning shortcuts that would not survive a different cell, temperature, duty cycle, or validation split.
For educational simulation data, the page should also preserve the reason the dataset was generated. Was it built to test feature extraction, compare split strategies, train a regressor, or explain a physical trend? The answer changes how the dataset should be used and which limitations need to be visible to readers.
Validation Questions
Before trusting a battery prediction workflow, ask whether the validation split separates the factor you care about. A row-level random split may test interpolation inside the same simulated regime, while a cell-level, parameter-level, cycle-level, or temperature-level split tests a harder question. The page should make that distinction explicit whenever SOH, RUL, impedance features, or aging labels are discussed.
The route also separates scientific interpretation from engineering deployment. A supervised model can help explore which features correlate with simulated aging labels, but a production BMS decision requires sensor validation, safety review, domain calibration, monitoring, and independent testing. That boundary is part of the content, not an afterthought.
Topic hub
Battery Modeling for AI Data
A PyBaMM route from model architecture and EIS spectra to a traceable labeled battery-aging data factory for AI training.
For PhD students and research engineers searching for PyBaMM, Oxford battery modeling, EISSimulation, SOH/RUL labels, LLI/LAM, and battery AI data generation.
Editorial notes
Why these articles belong in one route
The battery modeling hub emphasizes traceable data instead of treating simulation curves as real experimental conclusions. The articles separate model parameters, protocols, impedance spectra, aging state, and AI labels.
The PyBaMM route starts with the modeling pipeline and EISSimulation, then moves to aging data generation, SOH/RUL labels, and regression training. Each step keeps manifests or quality reports for leakage and generalization review.
This hub is aimed at research readers. It connects physics-based models, synthetic data, and machine learning evaluation while making clear that real applications still need experimental calibration.
What you will build
You will read PyBaMM as a modeling pipeline, run impedance and aging examples, and train SOH/RUL regressors.
Recommended reading order
Start with concepts, then move into runnable projects
Reading PyBaMM Fast: Architecture for Battery Modeling and AI Data
A PhD-level guide to PyBaMM expression trees, Simulation, model options, metadata, and AI dataset design.
PyBaMM EIS Data Generation: Impedance Features and AI Labels
Use PyBaMM core EISSimulation to generate impedance spectra, extract features, and align them with aging labels.
Generate Battery Aging and EIS AI Datasets with PyBaMM
Build a reproducible PyBaMM data factory for SOH, RUL, LLI, LAM, plating, and impedance-feature labels.
Training a Battery AI Model with PyBaMM: Predicting SOH and RUL
Train scikit-learn regressors on PyBaMM-style EIS features and operating metadata to predict battery SOH and RUL.
Resources and distribution assets
Code, data, diagrams, and share assets in one place
Battery Modeling for AI / GUIDE
PyBaMM AI Data Lab README
Setup, quick run, backend behavior, and output schemas for the PyBaMM battery AI data pipeline.
Battery Modeling for AI / ARCHIVE
PyBaMM AI Data Lab full bundle
Bundles design generation, aging sweeps, EIS sweeps, label building, validation checks, sample CSVs, and figures.
Battery Modeling for AI / DATASET
PyBaMM sample manifest
Stores sample id, model family, parameter set, protocol, temperature, SOC, cycle, split group, and label source.
Battery Modeling for AI / DATASET
PyBaMM EIS sample spectra CSV
Frequency-level impedance output with frequency, Z_re, Z_im, magnitude, phase, backend, and solver status.
Battery Modeling for AI / DATASET
Battery aging and EIS labels CSV
Stores SOH, RUL proxy, LLI, LAM, plating, local resistance, and EIS features.
Battery Modeling for AI / DATASET
PyBaMM AI data quality report
Records duplicate samples, duplicate spectrum points, missing labels, split leakage, and backend usage.
Battery Modeling for AI / DATASET
SOH/RUL training metrics CSV
Stores group split, MAE, RMSE, R2, label source, and backend used for auditing model results.
Battery Modeling for AI / DATASET
SOH/RUL held-out predictions CSV
Stores held-out true values, predictions, and absolute errors.
Battery Modeling for AI / DATASET
SOH/RUL feature importance CSV
Records random-forest feature importance values for each target model.
Battery Modeling for AI / DIAGRAM
PyBaMM to AI data pipeline figure
{kind=link}
Shows design grid, aging solve, EIS solve, label build, quality gate, and AI split.
Battery Modeling for AI / DIAGRAM
EIS feature and label schema figure
{kind=link}
Connects frequency points, impedance features, operating metadata, and SOH/RUL/degradation labels.
Battery Modeling for AI / DIAGRAM
Aging label sample figure
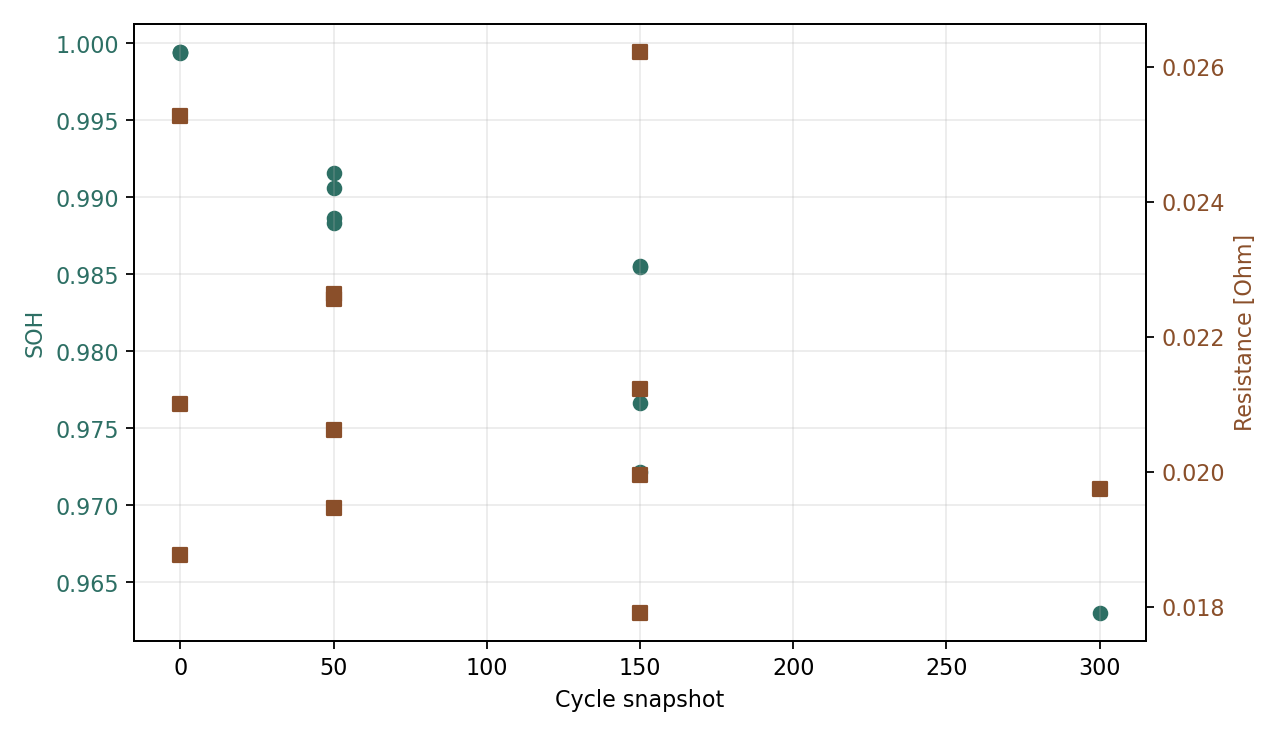{kind=link}
Sample figure showing cycle snapshots, SOH, and local ECM resistance labels.
Battery Modeling for AI / DIAGRAM
SOH/RUL training results figure
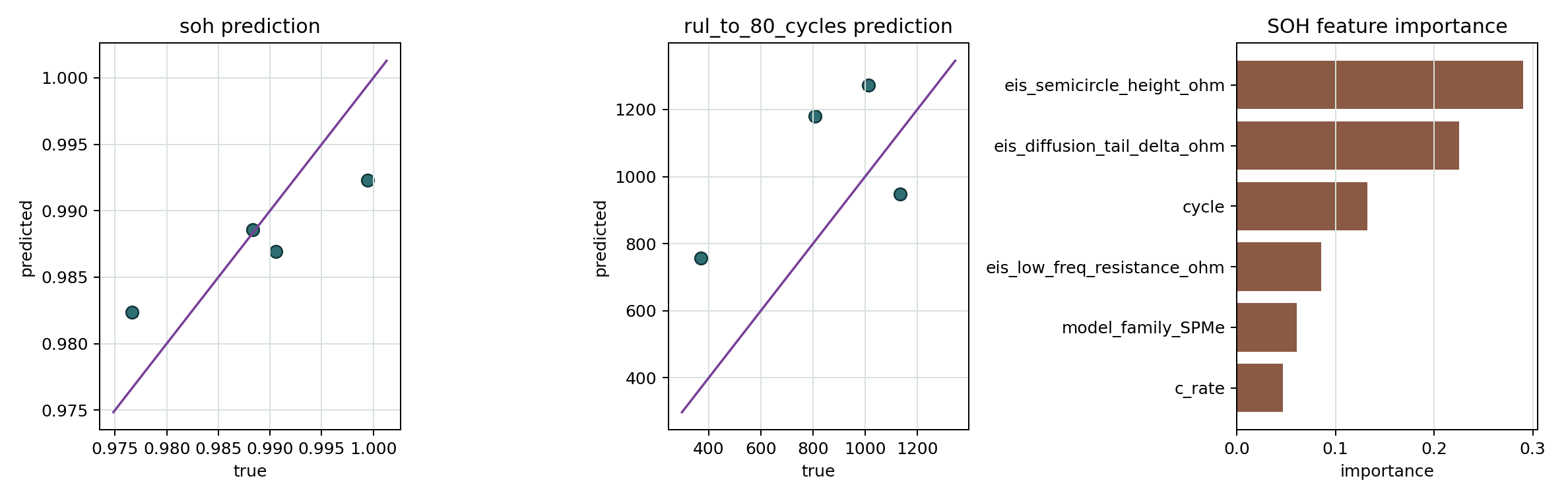{kind=link}
Shows held-out SOH/RUL prediction scatter plots and SOH feature importance.
Battery Modeling for AI / SOCIAL
Battery Modeling for AI share card
{kind=link}
OG share card for the PyBaMM battery modeling, EIS, aging simulation, and AI data hub.
FAQ
Direct answers to common search questions
Can these data replace real battery experiments?
No. They are physics-based synthetic data for pretraining, pipeline validation, and experiment design; real claims still need calibration and out-of-domain validation.
Why not use the old pybamm-eis package?
The old repository is archived. The articles and lab use pybamm.EISSimulation from PyBaMM core.
Why split by cell_design_id or protocol_id?
Frequency points and cycle snapshots from the same simulated trajectory are highly correlated; row-level random splits leak information.