
English
Transformer Attention Math: Q/K/V, Softmax Weights, Masks, and KV Cache
The core concept of a Transformer's Self-Attention mechanism can be intuitively understood as follows: every token in a sequence uses its own Query vector to evaluate the Key vectors of all other tokens. This process determines how "attention" should be distributed across the sentence, and finally, this weight distribution is used to compute a weighted sum of the information vectors (Values). Its mathematical expression is remarkably concise—just one line of code—but it conceals a staggering amount of engineering depth and model training nuances.
In this article, we will start from first principles. We will manually calculate Scaled Dot-Product Attention for a 3-token sequence and dive deep into Q/K/V projections, Softmax saturation, Causal Masking, Multi-head mechanisms, and the notorious inference performance beast known as the KV Cache.
1. The Core Mathematical Formula
This is the foundational equation of the Large Language Model era:
Attention(Q, K, V) = softmax((Q @ K^T) / sqrt(d_k)) @ VBreaking it down:
Q @ K^Tproduces an attention score matrix of size `[seq_len, seq_len]`. Because it's a dot product, it measures the "similarity" or "affinity" between pairs of tokens in a high-dimensional space.- Why must we divide by
sqrt(d_k)? Suppose Q and K have a dimension of `d_k = 4096`, and their elements follow an independent distribution with a mean of 0 and a variance of 1. The variance of their dot product will scale up to `4096`. A massive variance creates extreme score values (e.g., 100 vs -100). When these are passed through a Softmax function, it forces the gradients to near-zero (vanishing gradients), a problem known as "Softmax saturation."
2. Architectural Diagram: Data Flow and Dimensions
graph TD
Input[Input Sequence: B, L, d_model] --> WQ(W_q Linear)
Input --> WK(W_k Linear)
Input --> WV(W_v Linear)
WQ --> Q[Q: B, h, L, d_k]
WK --> K[K: B, h, L, d_k]
WV --> V[V: B, h, L, d_v]
Q --> Dot[Dot Product: Q @ K^T]
K --> Dot
Dot --> Scale[Scale by 1/sqrt(d_k)]
Scale --> Mask[Apply Causal Mask]
Mask --> Softmax[Softmax along dim L]
Softmax --> AttentionWeights[Attention Weights: B, h, L, L]
AttentionWeights --> MatMulV[MatMul with V]
V --> MatMulV
MatMulV --> Context[Context Output: B, h, L, d_v]
Context --> Concat[Concat Heads: B, L, d_model]
Concat --> Out[W_o Linear]
3. Practical Demonstration: Self-Attention in NumPy
Formulas can be abstract. Let's run a highly educational, purely Pythonic NumPy implementation. Imagine our input sequence consists of just 3 tokens (e.g., "AI", "needs", "math") with an embedding dimension of 4:
import numpy as np
# 1. Simulate Q, K, V Matrices (Seq_len=3, d_k=4)
# Representing tokens: "AI", "needs", "math"
Q = np.array([
[ 1.0, 0.5, -0.2, 0.1], # AI
[-0.5, 1.2, 0.8, -0.4], # needs
[ 0.2, -0.1, 1.5, 0.9] # math
])
K = np.array([
[ 0.8, 0.4, -0.3, 0.0],
[-0.2, 1.0, 0.5, -0.1],
[ 0.1, -0.2, 1.1, 0.7]
])
V = np.array([
[ 1.0, 0.0],
[ 0.0, 1.0],
[-1.0, -1.0]
])
d_k = Q.shape[1]
# 2. Calculate Dot-Product Scores and Scale
scores = (Q @ K.T) / np.sqrt(d_k)
print("Scaled Scores:\n", scores)
# 3. Causal Mask
# Mask out future positions to prevent information leakage (cheating)
mask = np.triu(np.ones((3, 3)), k=1)
scores[mask == 1] = -np.inf
# 4. Softmax Normalization
def softmax(x):
e_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return e_x / e_x.sum(axis=-1, keepdims=True)
weights = softmax(scores)
print("Attention Weights:\n", np.round(weights, 3))
# 5. Value Weighting (Context Output)
context = weights @ V
print("Context Output:\n", context)
If you run this code, you'll observe that the first row (the word "AI") assigns attention weights exclusively to itself. The third row ("math") distributes its attention across the preceding two tokens. This perfectly demonstrates the essence of autoregressive models: they must synthesize historical context without peaking into the future.
4. What Does the Causal Mask Actually Change?
As demonstrated in the code above, in autoregressive generation tasks, if the model is currently predicting the 3rd token, it absolutely cannot "see" tokens 4 or 5. Right before the Softmax operation, we forcefully overwrite the upper triangular matrix of the attention scores to negative infinity (-inf). After passing through the Softmax, these specific weights are mathematically crushed to exactly 0. Therefore, the Mask does not delete tokens; rather, it performs a probabilistic cutoff, ensuring that illegal attention allocation is impossible.
5. An Engineer's Perspective: The VRAM Killer and KV Cache
Real-World Insight: In textbooks, you see elegant matrix multiplication. But in industrial LLM deployment, what you see is a relentless stream of OOM (Out of Memory) exceptions.
During inference, large language models operate token-by-token. When generating token $t+1$, the K and V matrices for the previous $t$ tokens remain completely identical! If we were to naively multiply the full L x d_model matrices over and over, the computational waste would be catastrophic.
The KV Cache is the ultimate space-for-time tradeoff.
- We allocate a massive contiguous block in the GPU VRAM to cache historically generated K and V tensors.
- For every new token generated, we only compute $Q_{new}, K_{new}, V_{new}$ for that single token, and strictly append $K_{new}$ into the VRAM cache block.
- **The Cost is Staggering:** For slightly longer contexts (even just 10K tokens), a single batch's KV Cache footprint can easily exceed the memory required to load the model weights themselves! This is exactly why the industry invented PagedAttention (the core of vLLM), MQA (Multi-Query Attention), and GQA (Grouped-Query Attention)—they are all desperate engineering hacks designed to shrink the KV Cache memory footprint.
6. Shape and Mask Checks
The easiest attention bugs are the ones that still produce a tensor. First, verify that batched attention uses batch x heads x tokens x dim and transposes only the final two dimensions for Q @ K^T. Then verify that the causal mask describes query-token to key-token visibility and broadcasts over batch and head. Finally, confirm that softmax is applied over the key dimension, not over the query dimension.
For the three-token toy example, every attention row should sum to approximately 1, future positions should be zero after masking, and the context output should have the same final dimension as V. A heatmap is useful for debugging, but it is not causal proof of why a model predicted a token; it only shows how the current weighted read used Value vectors.
7. Attention Verification Matrix
Self-attention often fails with code that runs but has the wrong semantics. Use the matrix below to audit the NumPy toy example here and to transfer the checks to batched, multi-head, or cached inference implementations.
| Check | Correct evidence | Common mistake |
|---|---|---|
| Score shape | Q @ K.T produces a query-token by key-token matrix. |
Transposing the wrong dimensions and mixing batch or head into attention. |
| Scaling and softmax | Scores are divided by sqrt(d_k); each row sums to about 1 over keys. |
Normalizing over queries, or skipping scaling and saturating attention early. |
| Causal mask | Future positions are near 0 after softmax while historical positions remain visible. | Reversing the mask so the current token sees the future but not the past. |
| KV cache | Each new token appends only K_new and V_new; history is not recomputed. |
Recomputing all K/V every step, or letting cache length drift from position encoding. |
8. Visualizations and Data Flow Summary
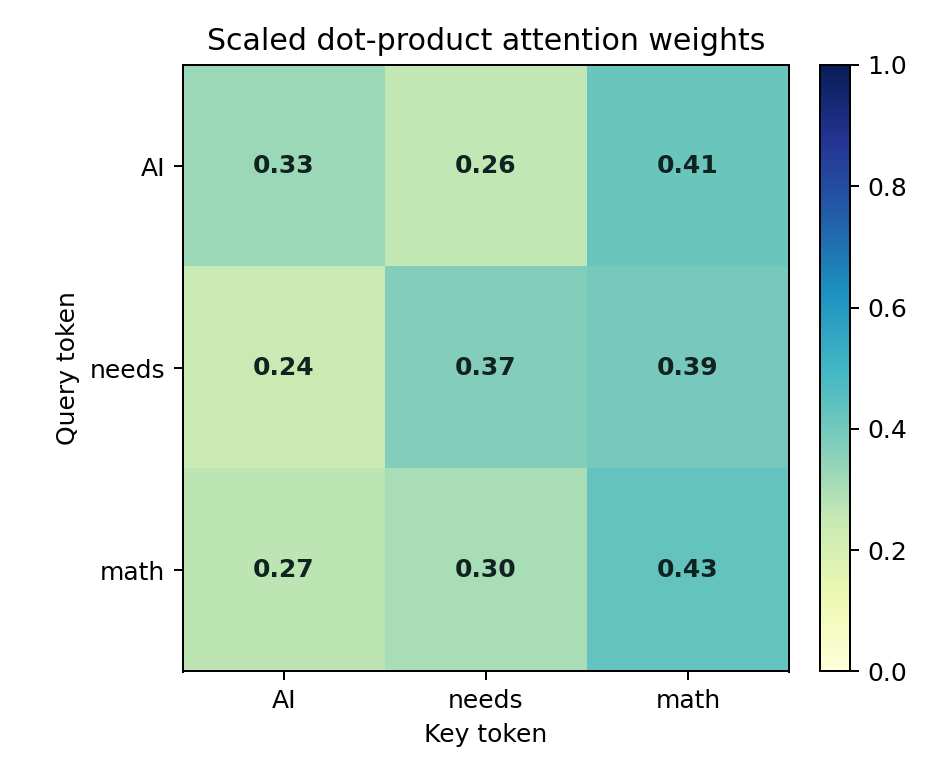
This mechanism may seem like simple linear algebra, but it currently supports the absolute frontier of global AI research. The next time your Transformer script crashes, your first instinct should always be: Print the shape of every single tensor, and trace the matrix multiplication on a piece of scrap paper.
Chinese
Transformer Attention 数学:Q/K/V、Softmax 权重、Mask 与 KV Cache
Open as a full pageTransformer 的注意力机制(Self-Attention)可以被通俗地理解成:序列中的每个词(token)用自己的查询向量(Query)去评估所有词的键向量(Key),从而决定对整个句子的“注意力分配”,最后再用这个分配权重去加权每个词的信息向量(Value)。它的数学形式仅仅短短一行代码,但在工程落地和模型训练中却暗藏无数细节。
本文将带你从第一性原理出发,使用 3 个 token 纯手工计算 Scaled Dot-Product Attention,并深入解析 Q/K/V 投影、Softmax 饱和、Causal Masking、多头机制(Multi-head)以及推理侧的性能怪兽——KV Cache。
一、核心数学公式解析
这是整个大语言模型时代的基石公式:
Attention(Q, K, V) = softmax((Q @ K^T) / sqrt(d_k)) @ V其中:
Q @ K^T产生的是一个 `[seq_len, seq_len]` 大小的注意力分数矩阵。由于是点积,它衡量了每对 token 之间在多维空间中的“相似度”或“关联度”。- 为什么必须除以
sqrt(d_k)?假设 Q 和 K 的维度 `d_k = 4096`,且元素服从均值为 0,方差为 1 的独立分布,那么点积的方差会高达 `4096`。方差过大会导致极端的分数值(如 100 和 -100),在经过 Softmax 时就会导致梯度几乎为零(梯度消失),即“Softmax 饱和”。
二、架构图解:数据流与维度变化
graph TD
Input[Input Sequence: B, L, d_model] --> WQ(W_q Linear)
Input --> WK(W_k Linear)
Input --> WV(W_v Linear)
WQ --> Q[Q: B, h, L, d_k]
WK --> K[K: B, h, L, d_k]
WV --> V[V: B, h, L, d_v]
Q --> Dot[Dot Product: Q @ K^T]
K --> Dot
Dot --> Scale[Scale by 1/sqrt(d_k)]
Scale --> Mask[Apply Causal Mask]
Mask --> Softmax[Softmax along dim L]
Softmax --> AttentionWeights[Attention Weights: B, h, L, L]
AttentionWeights --> MatMulV[MatMul with V]
V --> MatMulV
MatMulV --> Context[Context Output: B, h, L, d_v]
Context --> Concat[Concat Heads: B, L, d_model]
Concat --> Out[W_o Linear]
三、实战演示:用 Numpy 手写自注意力
光看公式太抽象,我们来跑一段可执行的 Numpy 纯手写代码。假设输入是一个只有 3 个 token(例如 "AI", "needs", "math")的序列,维度为 4:
import numpy as np
# 1. 模拟 Q, K, V 矩阵 (Seq_len=3, d_k=4)
# 代表 "AI", "needs", "math" 三个词
Q = np.array([
[ 1.0, 0.5, -0.2, 0.1], # AI
[-0.5, 1.2, 0.8, -0.4], # needs
[ 0.2, -0.1, 1.5, 0.9] # math
])
K = np.array([
[ 0.8, 0.4, -0.3, 0.0],
[-0.2, 1.0, 0.5, -0.1],
[ 0.1, -0.2, 1.1, 0.7]
])
V = np.array([
[ 1.0, 0.0],
[ 0.0, 1.0],
[-1.0, -1.0]
])
d_k = Q.shape[1]
# 2. 计算打分 (Scores) 并进行缩放 (Scaling)
scores = (Q @ K.T) / np.sqrt(d_k)
print("Scaled Scores:\n", scores)
# 3. 因果掩码 (Causal Mask)
# 屏蔽未来位置,防止模型作弊
mask = np.triu(np.ones((3, 3)), k=1)
scores[mask == 1] = -np.inf
# 4. Softmax 归一化
def softmax(x):
e_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return e_x / e_x.sum(axis=-1, keepdims=True)
weights = softmax(scores)
print("Attention Weights:\n", np.round(weights, 3))
# 5. 值加权 (Context)
context = weights @ V
print("Context Output:\n", context)
跑完这段代码你会发现:第一行对应 "AI" 这个词,它的注意力权重只会分配给自己;而第三行的 "math" 会将注意力分配给前两个词。这就体现了自回归模型的本质:只能用历史信息生成未来信息。
四、因果掩码(Mask)到底改变了什么?
正如上面代码所示,在自回归(Autoregressive)生成任务中,如果当前在预测第 3 个词,它绝不能“看到”第 4、5 个词的信息。我们在 Softmax 之前,强行把上三角矩阵的注意力分数赋值为负无穷大(-inf)。经过 Softmax 后,这些位置的权重会被精确地压为 0。所以,Mask 不是删除 token,而是在概率层面做切断,让非法的注意力分配变成绝对不可能发生的事。
五、工程师的填坑经验:显存杀手与 KV Cache
实战视角:在书本上你看到的是优雅的矩阵公式,但在工业界部署 LLM 时,你看到的往往是一次次无情的 OOM (Out of Memory) 报错。
在推理阶段,大模型是以逐字生成(Token-by-token)的方式运行的。生成第 $t+1$ 个词时,前面的 $t$ 个词的 K 和 V 都是完全不变的!如果我们每次都用全尺寸的 L x d_model 矩阵去重新乘一遍,那就是巨大的算力浪费。
KV Cache 的本质,就是用空间换时间。
- 我们会在 GPU 显存里开辟一块连续区域,把历史生成的 K 和 V 保存下来。
- 每生成一个新词,只需要计算当前这 1 个 token 的 $Q_{new}, K_{new}, V_{new}$,然后把 $K_{new}$ 拼接到显存里。
- 代价极其高昂:一个稍微长一点的上下文,哪怕只有 10K tokens,单 batch 消耗的 KV Cache 可能就会超过模型权重本身的显存占用!这就是为什么现在工业界会发明 PagedAttention(vLLM 的核心)、MQA (Multi-Query Attention) 和 GQA (Grouped-Query Attention),全都是为了削减 KV Cache 的显存体积。
六、实现时最容易错的三个 shape
第一处是 batch 维度。教学代码经常写成 Q @ K.T,这只适合单个序列;真实模型通常是 batch x heads x tokens x dim。这时应当转置最后两个维度,而不是把 batch 或 head 维度也混进去。shape 写错时,程序有时不会报错,只会通过广播得到完全错误的注意力矩阵。
第二处是 mask 维度。自回归 mask 应该覆盖 query-token 到 key-token 的二维关系,并且能广播到 batch 和 head。padding mask 则表示哪些 token 是填充位。两类 mask 的语义不同,不能简单相加了事。第三处是 softmax 的轴,必须沿 key 维度归一化;如果沿 query 维度归一化,每一列会变成概率分布,注意力含义就反了。
七、怎么检查 attention 实验结果
最基础的检查是每一行 attention weight 的和是否接近 1。然后检查 mask 后的未来位置是否接近 0。再检查 context 的 shape 是否和 Value 的最后一维一致。对于这篇文章里的三个 token toy example,你还可以手算第一行 softmax,确认权重变化不是因为代码排序错误或 mask 方向写反了。
注意力热力图适合调试,但不等价于完整解释。一个 token 权重高,只表示这一步加权读取更多地使用了某个 Value;它不直接证明模型“因为什么原因”做出最终预测。把 heatmap 当成排查工具,而不是因果证据,能避免很多误读。
八、Attention 验证矩阵
自注意力实现最容易出现“shape 能跑但语义错”的问题。下面的矩阵把检查点固定下来,读者可以用它复核本文的 NumPy toy example,也可以迁移到批量、多头或推理缓存实现中。
| 检查点 | 正确证据 | 常见错误 |
|---|---|---|
| score 形状 | Q @ K.T 得到 query-token 到 key-token 的二维矩阵。 |
转置错维度,把 batch/head 维度混进注意力矩阵。 |
| 缩放与 softmax | 除以 sqrt(d_k) 后沿 key 维度归一化,每行和约等于 1。 |
沿 query 维度 softmax,或不缩放导致权重过早饱和。 |
| causal mask | 未来位置在 softmax 后接近 0,历史位置仍可分配权重。 | mask 方向反了,让当前 token 只能看未来而不能看历史。 |
| KV Cache | 新 token 只追加 K_new、V_new,历史缓存不重复计算。 |
每步重算全部 K/V,或 cache 长度与位置编码不同步。 |
九、图示与数据流总结
这套机制看似只是矩阵乘法,但却支撑起了当今很多前沿 AI 系统。下次再遇到 Transformer 报错时,第一反应应该是:打印所有张量的 shape,然后在纸上画一遍矩阵乘法的过程。
The core concept of a Transformer’s Self-Attention mechanism can be intuitively understood as follows: every token in a sequence uses its own Query vector to evaluate the Key vectors of all other tokens. This process determines how “attention” should be distributed across the sentence, and finally, this weight distribution is used to compute a weighted sum of the information vectors (Values). Its mathematical expression is remarkably concise—just one line of code—but it conceals a staggering amount of engineering depth and model training nuances.
In this article, we will start from first principles. We will manually calculate Scaled Dot-Product Attention for a 3-token sequence and dive deep into Q/K/V projections, Softmax saturation, Causal Masking, Multi-head mechanisms, and the notorious inference performance beast known as the KV Cache.
1. The Core Mathematical Formula
This is the foundational equation of the Large Language Model era:
Attention(Q, K, V) = softmax((Q @ K^T) / sqrt(d_k)) @ VBreaking it down:
Q @ K^Tproduces an attention score matrix of size `[seq_len, seq_len]`. Because it’s a dot product, it measures the “similarity” or “affinity” between pairs of tokens in a high-dimensional space.- Why must we divide by
sqrt(d_k)? Suppose Q and K have a dimension of `d_k = 4096`, and their elements follow an independent distribution with a mean of 0 and a variance of 1. The variance of their dot product will scale up to `4096`. A massive variance creates extreme score values (e.g., 100 vs -100). When these are passed through a Softmax function, it forces the gradients to near-zero (vanishing gradients), a problem known as “Softmax saturation.”
2. Architectural Diagram: Data Flow and Dimensions
graph TD
Input[Input Sequence: B, L, d_model] --> WQ(W_q Linear)
Input --> WK(W_k Linear)
Input --> WV(W_v Linear)
WQ --> Q[Q: B, h, L, d_k]
WK --> K[K: B, h, L, d_k]
WV --> V[V: B, h, L, d_v]
Q --> Dot[Dot Product: Q @ K^T]
K --> Dot
Dot --> Scale[Scale by 1/sqrt(d_k)]
Scale --> Mask[Apply Causal Mask]
Mask --> Softmax[Softmax along dim L]
Softmax --> AttentionWeights[Attention Weights: B, h, L, L]
AttentionWeights --> MatMulV[MatMul with V]
V --> MatMulV
MatMulV --> Context[Context Output: B, h, L, d_v]
Context --> Concat[Concat Heads: B, L, d_model]
Concat --> Out[W_o Linear]
3. Practical Demonstration: Self-Attention in NumPy
Formulas can be abstract. Let’s run a highly educational, purely Pythonic NumPy implementation. Imagine our input sequence consists of just 3 tokens (e.g., “AI”, “needs”, “math”) with an embedding dimension of 4:
import numpy as np
# 1. Simulate Q, K, V Matrices (Seq_len=3, d_k=4)
# Representing tokens: "AI", "needs", "math"
Q = np.array([
[ 1.0, 0.5, -0.2, 0.1], # AI
[-0.5, 1.2, 0.8, -0.4], # needs
[ 0.2, -0.1, 1.5, 0.9] # math
])
K = np.array([
[ 0.8, 0.4, -0.3, 0.0],
[-0.2, 1.0, 0.5, -0.1],
[ 0.1, -0.2, 1.1, 0.7]
])
V = np.array([
[ 1.0, 0.0],
[ 0.0, 1.0],
[-1.0, -1.0]
])
d_k = Q.shape[1]
# 2. Calculate Dot-Product Scores and Scale
scores = (Q @ K.T) / np.sqrt(d_k)
print("Scaled Scores:\n", scores)
# 3. Causal Mask
# Mask out future positions to prevent information leakage (cheating)
mask = np.triu(np.ones((3, 3)), k=1)
scores[mask == 1] = -np.inf
# 4. Softmax Normalization
def softmax(x):
e_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return e_x / e_x.sum(axis=-1, keepdims=True)
weights = softmax(scores)
print("Attention Weights:\n", np.round(weights, 3))
# 5. Value Weighting (Context Output)
context = weights @ V
print("Context Output:\n", context)
If you run this code, you’ll observe that the first row (the word “AI”) assigns attention weights exclusively to itself. The third row (“math”) distributes its attention across the preceding two tokens. This perfectly demonstrates the essence of autoregressive models: they must synthesize historical context without peaking into the future.
4. What Does the Causal Mask Actually Change?
As demonstrated in the code above, in autoregressive generation tasks, if the model is currently predicting the 3rd token, it absolutely cannot “see” tokens 4 or 5. Right before the Softmax operation, we forcefully overwrite the upper triangular matrix of the attention scores to negative infinity (-inf). After passing through the Softmax, these specific weights are mathematically crushed to exactly 0. Therefore, the Mask does not delete tokens; rather, it performs a probabilistic cutoff, ensuring that illegal attention allocation is impossible.
5. An Engineer’s Perspective: The VRAM Killer and KV Cache
Real-World Insight: In textbooks, you see elegant matrix multiplication. But in industrial LLM deployment, what you see is a relentless stream of OOM (Out of Memory) exceptions.
During inference, large language models operate token-by-token. When generating token $t+1$, the K and V matrices for the previous $t$ tokens remain completely identical! If we were to naively multiply the full L x d_model matrices over and over, the computational waste would be catastrophic.
The KV Cache is the ultimate space-for-time tradeoff.
- We allocate a massive contiguous block in the GPU VRAM to cache historically generated K and V tensors.
- For every new token generated, we only compute $Q_{new}, K_{new}, V_{new}$ for that single token, and strictly append $K_{new}$ into the VRAM cache block.
- **The Cost is Staggering:** For slightly longer contexts (even just 10K tokens), a single batch’s KV Cache footprint can easily exceed the memory required to load the model weights themselves! This is exactly why the industry invented PagedAttention (the core of vLLM), MQA (Multi-Query Attention), and GQA (Grouped-Query Attention)—they are all desperate engineering hacks designed to shrink the KV Cache memory footprint.
6. Shape and Mask Checks
The easiest attention bugs are the ones that still produce a tensor. First, verify that batched attention uses batch x heads x tokens x dim and transposes only the final two dimensions for Q @ K^T. Then verify that the causal mask describes query-token to key-token visibility and broadcasts over batch and head. Finally, confirm that softmax is applied over the key dimension, not over the query dimension.
For the three-token toy example, every attention row should sum to approximately 1, future positions should be zero after masking, and the context output should have the same final dimension as V. A heatmap is useful for debugging, but it is not causal proof of why a model predicted a token; it only shows how the current weighted read used Value vectors.
7. Attention Verification Matrix
Self-attention often fails with code that runs but has the wrong semantics. Use the matrix below to audit the NumPy toy example here and to transfer the checks to batched, multi-head, or cached inference implementations.
| Check | Correct evidence | Common mistake |
|---|---|---|
| Score shape | Q @ K.T produces a query-token by key-token matrix. |
Transposing the wrong dimensions and mixing batch or head into attention. |
| Scaling and softmax | Scores are divided by sqrt(d_k); each row sums to about 1 over keys. |
Normalizing over queries, or skipping scaling and saturating attention early. |
| Causal mask | Future positions are near 0 after softmax while historical positions remain visible. | Reversing the mask so the current token sees the future but not the past. |
| KV cache | Each new token appends only K_new and V_new; history is not recomputed. |
Recomputing all K/V every step, or letting cache length drift from position encoding. |
8. Visualizations and Data Flow Summary
This mechanism may seem like simple linear algebra, but it currently supports the absolute frontier of global AI research. The next time your Transformer script crashes, your first instinct should always be: Print the shape of every single tensor, and trace the matrix multiplication on a piece of scrap paper.
Search questions
FAQ
Who is this article for?
This article is for readers who want an intermediate-level guide to Transformer Attention Math. It takes about 14 min and focuses on Transformer, Attention, QKV, KV Cache.
What should I read next?
The recommended next step is LLM, RAG, and Agent Security, so the article connects into a longer learning route instead of ending as an isolated note.
Does this article include runnable code or companion resources?
Yes. Use the run notes, resource cards, and download links on the page to reproduce the example or inspect the companion files.
How does this article fit into the larger site?
It is connected to the article context block, learning routes, resources, and project timeline so readers can move from concept to implementation.
Article context
AI Learning Project
A practical route from AI concepts to machine learning workflow, evaluation, neural networks, Python practice, handwritten digits, a CIFAR-10 CNN, adversarial traffic-defense notes, and AI security.
Your next step
Continue: LLM VisualizerHand-calculate Q/K/V scores, softmax weights, masks, multi-head structure, and KV cache.
Download share card Open share center{kind=link}
Companion resources
AI Learning Project / DATASET
Attention weights CSV
Scores, softmax weights, and context vectors for a three-token scaled dot-product attention example.
AI Learning Project / DIAGRAM
Deep learning math figure set
{kind=link}
Includes matrix shapes, computation graphs, loss contours, convolution scans, and attention heatmaps.
AI Learning Project / TOOL
Deep learning math interactive visualizer
Browser modules for gradient checking, optimizer paths, convolution output size, and attention heatmaps.
Project timeline
Published posts
- AI Basics Learning Roadmap Separate AI, machine learning, and deep learning before going into implementation details.
- Machine Learning Workflow Follow the practical path from data and features to training, prediction, and evaluation.
- Model Training and Evaluation Understand loss, overfitting, train/test splits, accuracy, recall, and F1.
- Neural Network Basics Move from perceptrons to activation, forward propagation, backpropagation, and training loops.
- Matrix Calculus for Neural Networks Derive dL/dW for y = Wx + b and verify it with finite differences.
- Backpropagation as a Computation Graph Trace local gradients through ReLU and softmax cross-entropy in a two-layer MLP.
- Gradient Descent and Optimizer Geometry Compare gradient descent, momentum, and Adam on a visible quadratic loss surface.
- Convolution and Receptive Field Math Compute convolution output size, receptive fields, channel mixing, and im2col layout.
- Transformer Attention Math Hand-calculate Q/K/V scores, softmax weights, masks, multi-head structure, and KV cache.
- Python AI Mini Practice Run a small scikit-learn classification task and read the experiment output.
- Handwritten Digit Dataset Basics Read train.csv, test.csv, labels, and the flattened 28 by 28 pixel layout before training the classifier.
- Handwritten Digit Softmax in C Follow the C implementation from logits and softmax probabilities to confusion matrices and submission export.
- Handwritten Digit Playground Notes See how the offline classifier was adapted into a browser demo with drawing input and probability output.
- CIFAR-10 Tiny CNN Tutorial in C Build and train a small convolutional neural network for CIFAR-10 image classification, then read its loss and accuracy output.
- High-Entropy Traffic Defense Notes Study encrypted metadata leaks, entropy, traffic classifiers, and a defensive Python chaffing prototype.
- AI Security Threat Modeling Build a defense map with NIST adversarial ML, MITRE ATLAS, and OWASP LLM risks.
- Adversarial Examples and Robust Evaluation Evaluate clean and perturbed accuracy with an FGSM-style digits experiment.
- Data Poisoning and Backdoor Defense Study poison rate, trigger behavior, attack success rate, and training pipeline controls.
- Model Privacy and Extraction Defense Measure membership inference signal and surrogate fidelity against a local toy model.
- LLM, RAG, and Agent Security Separate instructions from data and enforce tool permissions against indirect prompt injection.
Published resources
- Python AI practice code guide The article includes a runnable scikit-learn classification script.
- digit_softmax_classifier.c The C source for the handwritten digit softmax classifier.
- train.csv.zip Compressed handwritten digit training set with 42000 labeled samples.
- test.csv.zip Compressed handwritten digit test set with 28000 unlabeled samples.
- sample_submission.csv The official submission format example for checking the final output columns.
- submission.csv The prediction file generated by the current C project.
- digit-playground-model.json The compact softmax demo model and sample set used by the browser playground.
- digit-sample-grid.svg A small handwritten digit preview grid extracted from the training set.
- Handwritten digit project bundle Contains the source file, compressed datasets, submission files, browser model, and preview grid.
- cifar10_tiny_cnn.c source Single-file C tiny CNN with CIFAR-10 loading, convolution, pooling, softmax, and backpropagation.
- model_weights.bin sample weights Model weights generated by one local small-sample run.
- test_predictions.csv sample predictions Sample test prediction output from the CIFAR-10 tiny CNN.
- CNN project explanation PDF Companion explanation material for the CNN project.
- Virtual Mirror redacted code skeleton A redacted mld_chaffing_v2.py control-flow skeleton with secrets, node topology, and target lists removed.
- Virtual Mirror stress-test template A redacted CSV template for CPU, memory, peak threads, pulse rate, latency, and error measurements.
- Virtual Mirror classifier-evaluation template A CSV template for TP, FN, FP, TN, accuracy, precision, recall, F1, ROC-AUC, entropy, and JS divergence.
- Virtual Mirror resource notes Notes explaining why the public resources include only redacted code, test templates, and architecture context.
- AI Security Lab README Setup, safety boundaries, and quick-run commands for the AI Security series.
- AI Security Lab full bundle Includes safe toy scripts, result CSVs, risk register, attack-defense matrix, and architecture diagram.
- AI security risk register CSV risk register template for AI threat modeling and release review.
- AI attack-defense matrix Maps attack surface, toy demo, metric, and defensive control into one CSV table.
- AI Security Lab architecture diagram Shows threat modeling, robustness, data integrity, model privacy, and RAG guardrails.
- FGSM digits robustness script FGSM-style perturbation and accuracy-drop experiment for a local digits classifier.
- Data poisoning and backdoor toy script Demonstrates poison rate, trigger behavior, and attack success rate on digits.
- Model privacy and extraction toy script Outputs membership AUC, target accuracy, surrogate fidelity, and surrogate accuracy.
- RAG prompt injection guard toy script Uses a deterministic toy agent to demonstrate external-data demotion and tool-policy blocking.
- Deep Learning Math Lab README Setup commands, script entry points, generated outputs, and figure notes for the math series.
- Deep learning math full lab bundle Bundles NumPy scripts, CSV outputs, formula diagrams, loss contours, convolution figures, and attention heatmaps.
- Gradient check results CSV Stores MSE analytic gradients, finite-difference gradients, and error norms.
- Optimizer path CSV Step-by-step coordinates and loss for gradient descent, momentum, and Adam on a 2D quadratic.
- Attention weights CSV Scores, softmax weights, and context vectors for a three-token scaled dot-product attention example.
- Deep learning math figure set Includes matrix shapes, computation graphs, loss contours, convolution scans, and attention heatmaps.
- Deep learning math interactive visualizer Browser modules for gradient checking, optimizer paths, convolution output size, and attention heatmaps.
- Deep Learning topic share card A 1200x630 SVG card for sharing the Deep Learning / CNN topic hub.
- Machine Learning From Scratch share card A 1200x630 SVG card for the K-means, Iris, and ML workflow topic hub.
- Student AI Projects share card A 1200x630 SVG card for handwritten digits, C classifiers, and browser demos.
- CNN convolution scan animation An 8-second Remotion animation showing how a 3x3 convolution kernel scans an input and builds a feature map.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Current route
- AI Basics Learning Roadmap Learning path step
- Machine Learning Workflow Learning path step
- Model Training and Evaluation Learning path step
- Neural Network Basics Learning path step
- Matrix Calculus for Neural Networks Learning path step
- Backpropagation as a Computation Graph Learning path step
- Gradient Descent and Optimizer Geometry Learning path step
- Convolution and Receptive Field Math Learning path step
- Transformer Attention Math Learning path step
- LLM Visualizer Learning path step
- Python AI Mini Practice Learning path step
- Handwritten Digit Dataset Basics Learning path step
- Handwritten Digit Softmax in C Learning path step
- Handwritten Digit Playground Notes Learning path step
- CIFAR-10 Tiny CNN Tutorial in C Learning path step
- High-Entropy Traffic Defense Notes Learning path step
- AI Security Threat Modeling Learning path step
- Adversarial Examples and Robust Evaluation Learning path step
- Data Poisoning and Backdoor Defense Learning path step
- Model Privacy and Extraction Defense Learning path step
- LLM, RAG, and Agent Security Learning path step
Next notes
- Add more image-classification and error-analysis cases
- Turn common metrics into a quick reference
- Add more AI security defense experiment notes